
Building the Right Benchmarks for Vertical AI
Inside Column Tax’s TaxCalcBench, and what every applied-AI team can learn from it

Benchmarks are the operating system for product truth. But most generic evals miss the factors that actually define success in real-world verticals. Factors like domain rules, tool use, and the need for auditable, line-item-level correctness.
This week, I sat down with Michael Bock, CTO and co-founder of Column Tax, to unpack why vertical benchmarks matter, how they built one for the tax industry called TaxCalcBench, and how other founders can adopt similar playbooks across verticals.
The Current Landscape of Benchmarks
The world of AI evals is still early and messy. This is particularly true for domains with multi-step workflows, high context requirements, and legally binding outcomes. Michael described today’s landscape as “a bit of a wild west,” where every company is inventing its own evaluation system because standardized tooling simply doesn’t exist. He told me that “since agents are still such a new phenomenon, every company is coming up with their own ways of creating evals and benchmarks.”
There are promising signs of progress: projects like OpenAI’s GDPval and Penrose’s AccountingBench are beginning to push evals into domain-specific territory. But most benchmarks still test one-shot, self-contained tasks, which bear little resemblance to the messy, multi-form, multi-rule reality of industries like tax, healthcare, insurance, or compliance. Benchmarks that capture realistic, full-task behavior (like Sierra’s τ-bench) are still the exception. “Reality has a surprising amount of detail,” Michael said, referencing John Salvatier’s essay and noting how difficult it is to capture true multi-step workflows in simulation.
Even building the test harness itself required Column Tax to start from scratch. A test harness is the software around your tests that handles all the plumbing, feeding inputs to a model/agent, collecting outputs, comparing them to expected results, and generating metrics. “I built a custom benchmarking harness, but would have been happy to use something off-the-shelf if there had been something available,” he said.
As domains get more specialized, we’re seeing that same pattern repeat itself. Companies are increasingly relying on high-expertise labeling rather than generic annotators; OpenAI is reportedly hiring former bankers for financial evals, and firms like Mercor are capitalizing on this trend.
In tax, where the underlying rules span more than 75,000 pages, Column Tax realized they were one of the few companies with both the expertise and the data to create a tax-specific benchmark.
Designing a Benchmark
Column Tax is on a mission to automate tax filing and make it so every taxpayer can file confidently in one-click. Their first product is embedded, DIY tax filing software. The company has already filed more than a million returns and built what they believe is the first fully featured U.S. personal income tax engine developed in decades. “There are very few companies in the U.S. that have an income tax ‘engine’ that can actually compute tax returns. Even the IRS doesn’t have that software in-house!” said Michael. In other words, the industry has almost no shared infrastructure or open literature.
Against that backdrop, designing TaxCalcBench became an exercise in identifying the “atomic unit” of the filing workflow most essential for model evaluation. Column Tax breaks the workflow into three subtasks:
Document collection
Preparation
Calculation
The calculation step, which is turning thousands of pages of English instructions into exact Form 1040 outputs, was both the hardest and the most important part. “We decided to build a benchmark there first. I imagine, over time, we’ll build benchmarks for the other two subtasks,” Michael told me.
To build the benchmark, they released a public slice of their internal test suite: 51 realistic TY24 federal-only cases, each paired with a deterministic engine output. The harness evaluates strict correctness (the only standard that matters for tax), a lenient +/-$5 band to understand near misses, and repeat-run reliability (does the model get worse as you sample more often?). This last metric matters because model variance can mask brittleness; best-of-N tests often hide inconsistencies that show up in production.
Column Tax intentionally began with simple cases. “Since this task is very hard today for AI, we started by including just the easiest sample tasks like simple tax situations, and federal-only returns. Over-time, I imagine we’ll include more complex tax situations and state returns as well,” Michael noted.
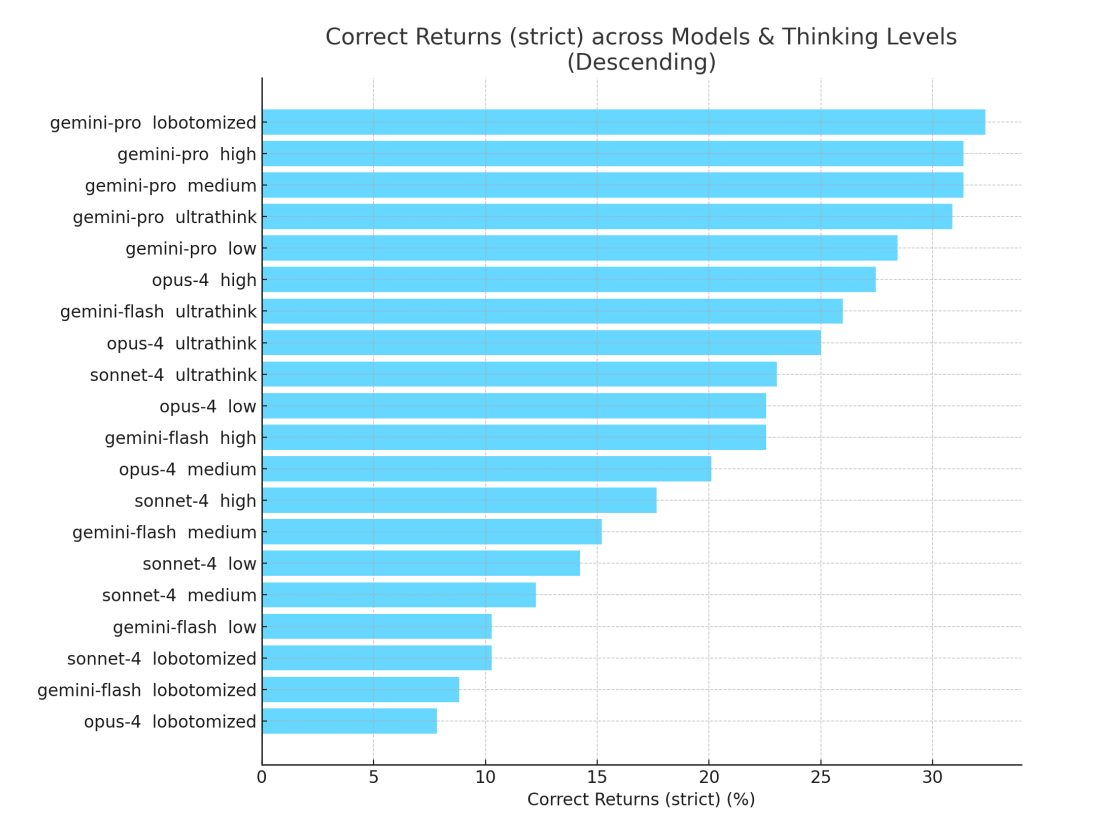
What the Results Revealed
The results revealed that even top frontier models correctly compute fewer than a third of returns under strict criteria. “For me, these results were a good reminder that while these large models are incredible in many ways, they have billions or trillions of parameters and so when competing with deterministic code on verifiable tasks, they still have a long way to go,” he said. The model miss patterns revealed two broad classes of failure.
First, knowledge gaps. Tax filing requires access to the latest forms and instructions, which change every October-December. Without up-to-date guidance, models hallucinate, apply outdated rules, or misinterpret thresholds. Tool use (like web search) helps, but doesn’t eliminate the issue.
Second, and more significantly, were eligibility and calculation mistakes. Models often misapply credit rules, mishandle multi-form interactions, or fail to follow mandated IRS tools like tax tables. A common pattern in the evals was watching models compute taxes using percentage brackets rather than using the official lookup table, a small numerical error that still leads to an invalid return. Michael concluded that “LLMs simply are not good enough yet at reading and analyzing tax law, they consistently misunderstand and misapply the rules.”
Reliability also degraded as Column Tax increased the number of samples. Models that looked competent in best-of-N settings became inconsistent when evaluated repeatedly, underscoring how fragile their reasoning still is.
These insights became essential inputs into the development of Iris, Column Tax’s tax-development agent. Iris converts tax law into code, then continuously tests itself against the benchmark. “One of the most important steps in building Iris is the Formula-Writer ↔ Evaluator loop,” Michael said. “The agent writes code, gets evaluated, learns, and moves gradient-descent style toward the correct output.” Because the outputs are deterministic, the entire pipeline is fully automated.
The benchmark also surfaced important differences in how models respond to performance-tuning levers. On the reasoning side, Claude models improve dramatically with more test-time compute, while Gemini barely moves, and GPT models sit somewhere in between. These differences now influence how Column Tax allocates its compute budget and selects providers.
On the prompting side, the team found that small details mattered just as much. “Prompt design is still super important,” Michael emphasized. “Detailed instructions and a good format guide make a huge difference.”
Perhaps the most important insight is how the results shaped their technical roadmap. The benchmark confirmed that models are still far from being able to compute taxes unaided. This finding validated Column Tax’s strategy to double down on Iris rather than trying to outsource that reasoning to raw LLM outputs.
Vertical Benchmarks as a Moat
“If you’re building any sort of AI or agent-based functionality, you need an eval – full stop,” Michael said, noting that “building an agent without an eval is like trying to drive a car blindfolded.”
Accuracy-critical industries demand proof, and benchmarks will be the mechanism that delivers it. Vertical benchmarks compound. They codify institutional knowledge, edge cases, and industry-specific nuances. They become the quality gate every new prompt, model, or agent must clear. And they serve as proof to customers that the system works consistently.
Benchmarks guide strategy. “Should I build this by-hand? Build a feature on top of a model? Or train a model myself to do this task? A benchmark helps you answer that strategy question,” he explained.
Data quality matters enormously. Building a benchmark without reliable good data is meaningless. As Michael put it, the law of “garbage in, garbage out” applies more strongly in evals than perhaps anywhere else. “Getting good data is really hard,” he said. “We had to get creative recruiting what we think is the best personal-income tax SME team in the country.”
Benchmarks are becoming the backbone of applied AI. TaxCalcBench is a blueprint for how to create one that is rigorous, useful, and defensible. Benchmarks become not only an accuracy check, but also a strategic asset, the thing that keeps your agents honest and your product grounded in reality.
“Vertical benchmarks will continue to evolve to more realistically model the real-world,” Michael concluded. “As AI advances to handle more and more of the economy, benchmarks will have to be at the forefront.”
I really enjoyed doing this interview! I think you captured the essence of where we are at with vertical AI benchmarks so well - amazing work Annelies! Thanks for pushing the industry forward.