
Designing the Right Synthetic Engines
Why Robotic Data Doesn’t Scale (Yet), and How Generative Simulation Changes That

This week, I’m writing about a topic that I’m still learning about. I’m early in my understanding here, so consider this an exploration of what I’ve been reading and listening to.
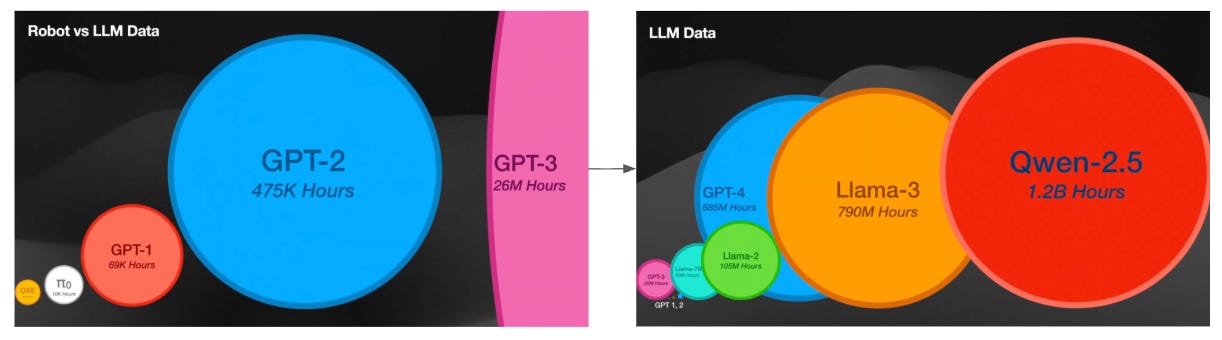
Ken Goldberg wrote an editorial last week called Good old-fashioned engineering can close the 100,000-year “data gap” in robotics. One of the footnotes compares the size of robot data to LLM data: it would take a human 100,000 years to consume the text and images used to train today’s LLMs; the comparable dataset for robots simply doesn’t exist.
Robotic training data is small, expensive, and deeply local. A robot in a warehouse can only learn from that warehouse. If the lighting changes or the floor texture is different, it stumbles. Teleoperation, which is where humans guide robots through VR rigs, is slow and labor-intensive. And unlike language models, there’s no internet-scale corpus of robot interaction data to scrape. This scarcity is why robots often fail to generalize.
Large language models exploded once they had access to trillions of words online. Robotics has no equivalent, it is still stuck in the pre-GPT era.
The opportunity, therefore, is in designing engines that can manufacture this data, evolving with minimal human input and turning robotics into a compounding system like LLMs but grounded in physics.
Digital Twins to Digital Cousins
In a recent talk, Jim Fan described the evolution from digital twins to digital cousins. Digital twins focused on building virtual copies of robots and their environments. With GPUs, you can spin up thousands of parallel simulations, run them faster than real time, and randomize things like friction, lighting, or object weight.
That approach has worked. It’s how humanoids can learn to walk after the equivalent of “ten years” of training in just a few hours, or why robot hands can learn dexterous tricks like pen-spinning. Digital twins made sim-to-real transfer possible.
But digital twins have their limits. Every new environment (a grocery store instead of a warehouse, for example) requires painstaking, hand-built assets (CAD models, collision geometries, scene setups). Digital twins are fast, but brittle.
The next leap is generative simulation. Last year, researchers at Stanford published a paper on “digital cousins”, which automatically generate virtual scenes that share the same action possibilities as the real world but with variations. Unlike digital twins, which replicate a single environment exactly, digital cousins expand the training distribution, making skills more robust and transferable.
Instead of hand-crafting every scene, world-model pipelines use gen AI to produce endless variations. Diffusion models can recreate the same box out of cardboard, plastic, or metal. LLMs can lay out kitchens with counters at different heights or generate a variety of different warehouse aisle configurations. Video models can simulate a cup wobbling as it’s set down, or a human handing an object from a new angle. Even the physics (lighting, gravity, friction) can be randomized automatically.
With this approach, a single teleoperation demo becomes the seed for thousands of synthetic variations. Record a robot placing a box on a warehouse shelf, and you can generate different box textures, new racking layouts, and alternative grasp motions.
Generative sim also unlocks counterfactuals, the “what ifs” that you couldn’t collect in real life:
What if the robot dropped the box halfway?
What if the floor was slippery?
What if the aisle lighting was dim or flickering?
What if a forklift drove past and partially blocked the robot’s reach?
World models imagine plausible variations, creating compounding engines and broadening what robots can handle beyond the scope of the original demo.
Why It Matters
Once synthetic data pipelines start compounding, the bottleneck shifts from collecting demos to designing engines that generate them. These engines become the new flywheels of robotic intelligence.
Therefore, designing an engine that can generate the right demos repeatedly at scale is critical. The engine needs to be able to:
Define simple rules for generating lots of realistic scenes
Automatically vary physics (friction, lighting, weight) to expose edge cases
Standardize how tasks and preferences are phrased
Create tests that measure whether skills really work in the real world
With this approach, the engine can learn with minimal human input and its training accelerates exponentially. Generative simulation will multiply experience by orders of magnitude, turning a handful of demos into millions of trials and doing for robotics what GPT did for language.
Agreed, shared similar thoughts a few weeks ago.
The diffusion simulation approach is promising for scaling, but I'm curious whether synthetic engines can capture the actual "texture" of reality.
Bottleneck seems to be the precision of the physics engine.