
Process Innovation & The AI Stack in Chemicals

The Chemicals Slowdown
This BCG article about the slowdown in the chemical industry reminded me of what’s happening in the freight industry. Both markets are stuck in a perfect storm of overcapacity, soft demand, and margin pressure. Chemicals has had it rough since 2022. New capacity in Asia, tariffs and sanctions, supply reroutes, and an influx of imports from China are crushing utilization and pricing.
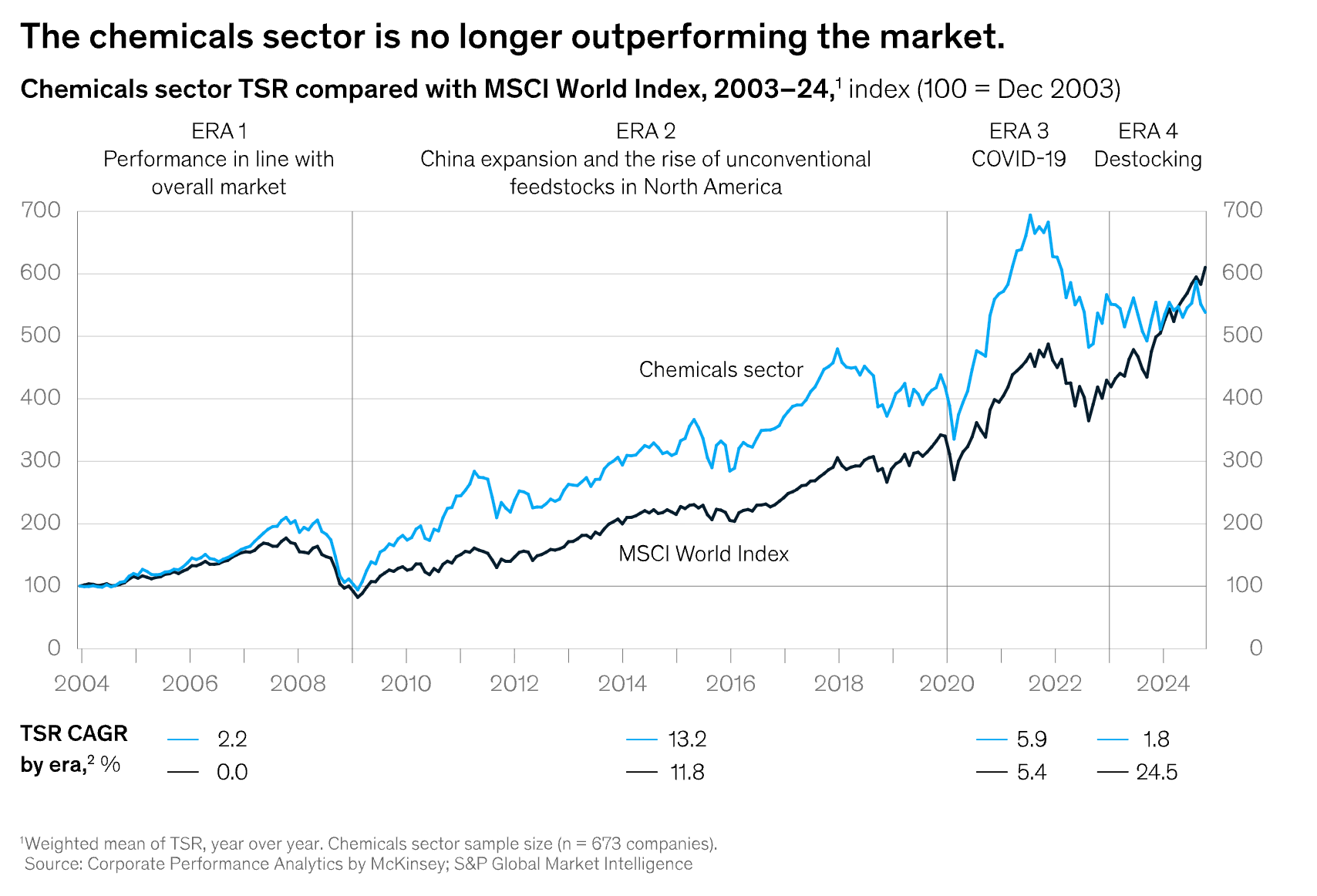
But unlike freight, the chemicals industry relies heavily on R&D and engineering, and R&D is painfully slow. Route scouting to lab work to scale-up can take 18 to 24 months. Knowledge lives in PDFs, ELNs, and memory. Plants collect time series data from PI, SCADA, and DCS, but analytics quality is inconsistent and cross-plant benchmarking is mostly manual. Teams are aging, and there aren’t enough chem-savvy sales engineers available to fill the gaps of those retiring. PFAS and chemical regulation, which I wrote about a couple weeks ago, add friction. SDS and EHS documents are heavy lifts to maintain and mine, and data quality gaps bleed into operations.
Material Discovery vs. Process Innovation
As background, it’s worth distinguishing two very different fronts of innovation in chemicals. Material discovery is where most of the funding headlines are today. These are the startups using generative models to propose new molecules or materials with desired properties. This is an area where simulation and prediction can go a long way, and success is often measured in how well models explore the design space before a single experiment runs.
Process innovation, on the other hand, lives closer to the plant. It’s less about inventing new molecules and more about optimizing how they’re made: tuning conditions, catalysts, and feedstocks to improve yield, cost, or sustainability. Here, AI has to integrate with the physical world. It’s an nth-level optimization problem that depends on continuous data and real-world feedback.
In this piece, I’m focusing primarily on opportunities in process optimization rather than material discovery.
Why AI Now?
There are three converging trends happening now that make the chemicals industry ripe for AI disruption.
Data is finally usable: Historians, ELNs, and open reaction datasets are more accessible. In other words, the data that chem companies have been collecting for years is now machine-readable, accessible via APIs/cloud, and labeled well enough that models can learn from it without months of cleanup.
Models have leveled up: Retrosynthesis and reaction prediction work, and hybrid physics plus ML is now production-grade.
Operational urgency is real: The energy transition, tariffs and supply shocks, and talent gaps are forcing faster cycles in R&D and go-to-market.
This means there’s an opportunity to build a more comprehensive AI stack that links lab to plant to commercial motions.
While these tailwinds are real, generic large language models aren’t built to handle the realities of chemistry. The next leap in process innovation for the industry will come from chemistry-native models that understand structure, constraints, and feedback.
The Problem with Generic LLMs
General LLMs won’t solve process innovation for three main reasons:
The data isn’t there (or clean): Only a small slice of real chemistry shows up in public corpora (one person I spoke to told me it’s only on the order of ~10% of known reactions!). The rest lives in messy ELNs, CRO hand-offs, and PDFs that weren’t designed for machine learning.
LLMs don’t natively “speak” chemistry: Generic LLMs are trained for natural language, not chemical languages and structures. SMILES (and cousins like InChI, SELFIES, reaction SMILES) have strict grammars, canonicalization quirks, and semantics (stereochemistry, valence, charge) that break generic LLM tokenization. Without chemistry-aware encoders/decoders, you get plausible text that maps to impossible molecules or routes.
No built-in verifiers for physics and safety: Out of the box, LLMs don’t enforce mass/charge balance, thermodynamics, or kinetics; they also don’t check SDS/EHS, unit consistency, or permit implications. Process innovation needs hard constraints and verifiers (physics-informed models, grammar-constrained decoding, stoichiometry/thermo checks, and simulators/controllers) that keep suggestions inside the feasible operating envelope.
Generic LLMs can still help with literature mining and hypothesis generation, but for process R&D you need chemistry-native models, verifiers, and a closed experimental loop. A physical experimentation layer is essential to generate high-velocity, high-quality data and labels. High-throughput experimentation (HTE) and simulation can strengthen this loop, with active learning deciding what to test next, ensuring the system learns from real outcomes and stays physically consistent.
Process Innovation R&D: Moving From Point Tools to Closed Loops
The first wave of AI in chemical R&D showed what was possible. IBM RXN and MIT’s ASKCOS made reaction prediction and synthesis planning mainstream for the early adopters. Those systems arrived around 2018.
The opportunity now is to go deeper and tighter:
Next-gen synthesis models that learn from larger, cleaner datasets and better architectures.
Vertical models for specific subsectors like materials, agrochem, and pharma where constraints and objectives differ.
True workflow control. Not just “predict a route,” but orchestrate literature review, hypothesis, experiment selection, and feedback into the model.
Companies like Mstack are showing what’s possible, reducing 18-24 month process development to 3 months, with ambitions to reach under 2 weeks. Their approach, which uses custom chemistry transformers on top of foundation models combined with proprietary experimental data, demonstrates how startups can outmaneuver generic LLMs. They pair it with a physical experimentation and commerce layer to not only unlock value but also reduce the time from lab to commercialization, collapsing what used to be a handoff between discovery, scale-up, and market launch into one continuous loop.
On the sourcing and scale-up side, like Mstack, Scimplify is building a full-stack specialty chemicals platform that connects R&D capabilities with a network of manufacturing partners, which is the kind of node where closed-loop discovery and commercialization can meet.
Two more R&D gaps that AI could solve:
Closed-loop optimization that marries Bayesian optimization with robotic platforms such as Chemspeed, Vapourtec, or Opentrons. Let the system pick and run the next best experiment, then update its beliefs.
Hybrid physics plus ML models that are both physically consistent and empirically accurate, and capable of running live in production instead of only in design studies. Pure ML models often fail to respect mass balance or thermodynamic constraints, predicting impossible reactions. Hybrid approaches embed these physical laws as hard constraints and use ML to learn kinetics.
Operations: Designing the New Chemicals Stack
Legacy players like AVEVA dominate plant operations with their Predictive Analytics and PI System offerings. But these systems were designed for a different era. They excel at data collection but struggle with modern AI integration and cross-plant learning. In the same way there is an opportunity to build a new industrial stack, there is an opportunity to build an AI-native chemicals stack that will:
Unify historian, LIMS, and maintenance data across sites, then enable transfer learning between similar units and processes.
Build prescriptive guidance with confidence bands and business impact. For example, they won’t stop at “this pump will fail” but will instead tell you the run-plan change, the expected uplift, and the SDS or permit implications.
Treat design conditions as a learning problem. As modular manufacturing scales, Solugen’s Bioforge concept is a useful reference point for low-emissions and flexible production. Pairing that kind of platform with AI to search operating spaces could compress process design cycles from years to months.
The promise here is improved yield, reduced energy intensity, higher Overall Equipment Effectiveness (OEE), and fewer off-specs.
Commercial: Solving the 10,000 SKU problem
Specialty chemical sellers often carry line-of-business portfolios with thousands of SKUs. Matching a customer’s product and process conditions and constraints to the right SKU can therefore take months. Corvus is going after that bottleneck, taking matching time from months to minutes without deep system integrations on day one.
Beyond that, there is a broader ecosystem forming around digital discovery and transactions. Knowde has shown there is strong market appetite for a marketplace where buyers can search, sample, quote, and purchase across suppliers. More recently, their focus has shifted toward deeper system integration, building the connective tissue between PIM, CRM, and ERP systems so suppliers can manage data and workflows more intelligently. There’s an opportunity to layer AI co-pilots and intelligent matching on top of that foundation so discovery, compliance checks, and quoting happen in the same flow.
Time to value is the shortest in this layer of the stack. You can often ship a pilot in weeks and show pipeline lift or cycle-time reduction inside a quarter. Plant integrations are still worth doing, but the commercial wedge gets you live data and budget faster.
Orchestration: Capturing the Flywheel
As with most verticals I’m exploring, the thing I’m most excited about is the connective tissue. Aka agentic workflows that coordinate end-to-end.
In R&D, the loop would be from literature and patent mining to route hypotheses to automated experiments to model updates to techno-economic screening to scale-up playbooks.
In commercial, the loop would be from account intel to SKU and formulation match to technical script to sample logistics to CRM updates and win-loss learning that feeds back into R&D priorities.
Every pass through the loop makes the system smarter. Proprietary datasets become the moat. Cycle times shrink. What once took months of R&D can happen in weeks, and sales close in days rather than quarters.
Chemicals has always been an industry of compounding knowledge. AI is simply a new accelerant. A way to compound knowledge faster, with tighter loops and fewer handoffs. The constraints of today’s slowdown aren’t just headwinds, but also catalysts for reinvention.