
The Agent Is Not the Product

At this point, most companies and individuals are using a relatively baseline level of AI models’ capabilities. Which means we don’t see huge benefits from each new model release. And yet, AI is still failing across many enterprise deployments. Why?
I think it’s because most enterprise AI conversations focus on the wrong question: what part of our budget can we put towards AI? For example, should we use our existing software like NetSuite or throw AI at it and move to a new AI-native ERP?
Whereas the right question is something more fundamental and not related to AI at all: what are our existing processes and where do they break down?
“You will not transform your company without rebuilding operations from the ground up,” Vas Moza, founder of Varick Agents, told me. Varick is an applied AI company that goes into large enterprise organizations to help them transform from the inside out with AI.
Rebuilding operations from the ground up means knowing what to automate deterministically, what to give to an agent, and what to leave to a human. This isn’t a model or agent engineering question. It’s a process engineering one. “That sort of process reengineering,” Vas said, “is what makes AI 100 times more effective.”
Not every workflow needs an agent
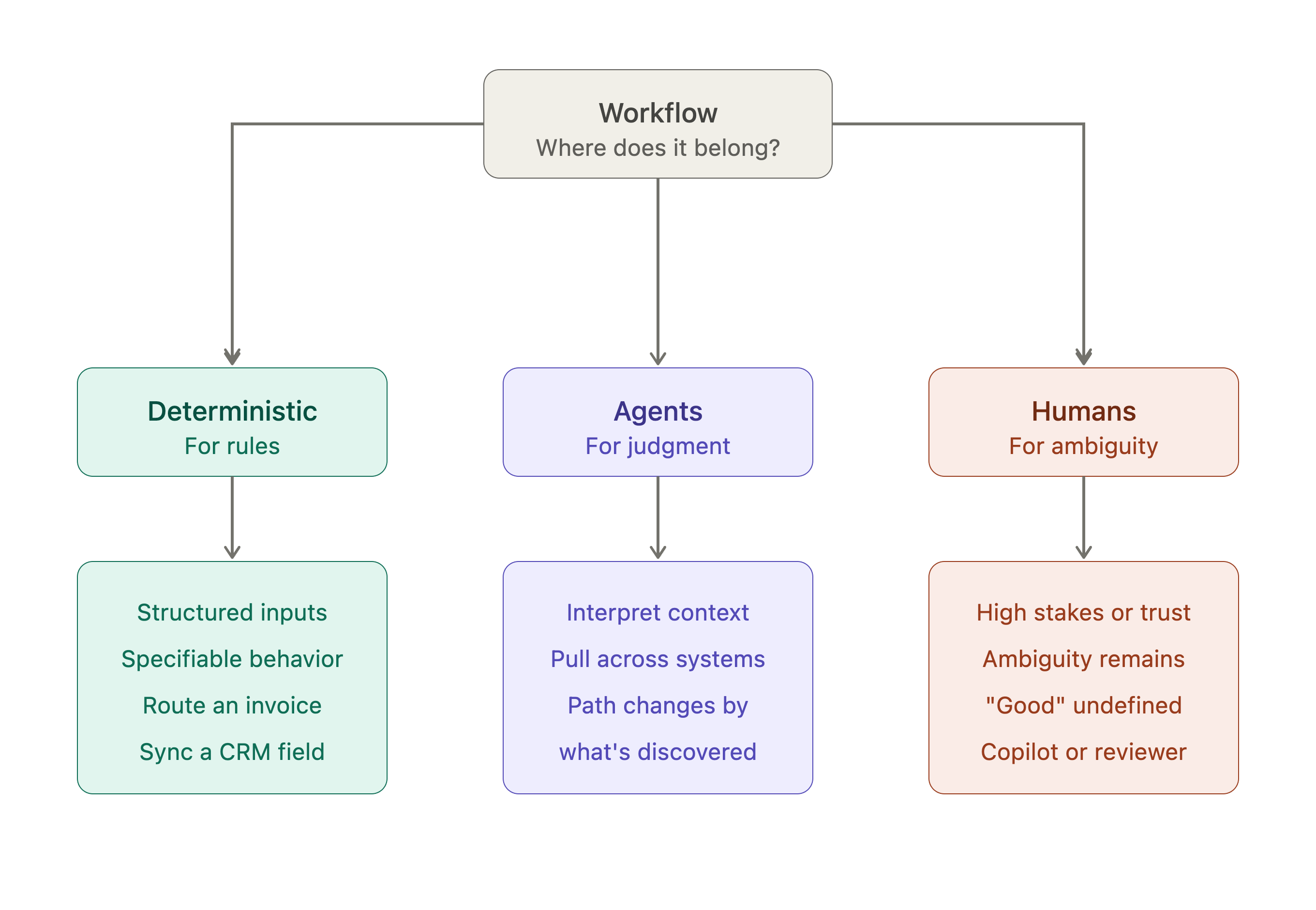
Knowing what not to agentify is the first question to answer when it comes to enterprise deployments – because not every workflow deserves an agent. My mental model for this is:
Deterministic automation is for rules.
If the inputs are structured and the desired behavior can be specified, you probably do not need an agent. You need software. These are for tasks like routing an invoice, syncing a CRM field, checking whether required documents are present. These workflows are valuable, but they don’t need open-ended reasoning.
Agents are for judgment under context.
Agents make sense when the work requires interpreting inputs, pulling context across systems, or executing a multi-step process where the path changes depending on what the agent discovers. The agent is useful where deterministic automation breaks down.
Humans are for accountability, ambiguity, and trust.
Some work should remain human. This might be because the consequences or relationships are too important, or the organization doesn’t yet know what “good” looks like. In these cases, the right AI product might be a copilot, reviewer, researcher, or QA layer.
Then, even once you know an agent is the right fit, you still have to decide whether it’s worth building. That’s a separate evaluation across dimensions like manual hour displacement, key-person risk, cycle-time reduction, revenue uplift, time and cost to build, and, most importantly, expected ROI. “A workflow with a 10x ROI should get prioritized,” Vas said. “A workflow with a 2x ROI maybe, maybe not. And a workflow with a sub 1x ROI should be left alone.”
The decision of where an agent belongs is downstream of all these diagnoses. Crucially, the most painful workflow isn’t necessarily the most valuable one to automate.
The deployment is the product
In many companies, the workflow lives in people, who sometimes can’t actually articulate what it is they’re doing. This is the tribal knowledge problem.
Before I was an investor, I built a company in the manufacturing and supply chain space. I remember trying to understand factory workflows by asking people what they did. They could always show me, but they rarely could explain it.
Vas sees the same thing in enterprise operations. The people doing the work aren’t usually used to narrating the work. They may have done it for fifteen years and know which exceptions are important to document versus which aren’t, but they may not have language for why.
And not all of that knowledge is worth capturing. Ahmad Kakar, CEO of Euclid, which builds agentic systems for trucking and logistics, told me, “The catch with tribal knowledge is that a considerable portion isn’t true expertise – it’s workarounds people built for non-existent or broken systems over the years. If you just capture it and encode it into the agent, you’ve automated the dysfunction. The work is pulling it out of people’s heads and then deciding what was real judgment versus scar tissue.”
The process is also a delicate one because the person whose knowledge you’re asking for often assumes their job is at risk. “We want to make sure they don’t feel like they’re having their entire job replaced,” Vas said, “because most of the time that isn’t the case. There’s a lot of work to be done at growing organizations.”
Troy Shen, co-founder of Cervo, an AI platform for customs brokers, frames the same dynamic as a sales problem. “Successful AI adoption takes two sales, not one,” he told me. “You’re selling an outcome to the executive and a dramatically better workday to the operator who’ll actually use the agents.” And without operator buy-in, the deployment will fail.
I spoke with Bihan Jiang, the Director of Product at Decagon, last year about this topic and she told me that a big chunk of her job is internal change management for customers, not just technical implementation. “There’s often a board-level directive to ‘bring AI into CX,’ which creates top-down momentum and we often end up being a part of many vibrant, cross-functional conversations on the customer’s side because there’s a lot of trust and alignment going into a decision this transformative.”
Suril Kantaria, co-founder of Adaptional, which builds agentic AI for insurance claims, frames the capture process as an apprenticeship. “In many enterprises, work is an apprenticeship model,” he told me. “This is a simple but key insight from deploying into some of the largest insurance companies. To succeed, we onboard like eager new hires — learn how the best adjusters handle claims, make decisions, ensure compliance, and keep up with internal policy. Core to the ‘product’ is both a deep understanding of our domain (insurance claims) and an ability to handle the contours of every customer’s claims process.”
This is what makes the deployment process partly technical, partly anthropological, and partly political. As Troy put it, “Deploy for a Fortune 500 and you’re rolling out across multiple offices, each with its own history, procedures, politics, and attitude toward AI. That navigation takes a rare mix of emotional intelligence, improvisation, and stakeholder management.”
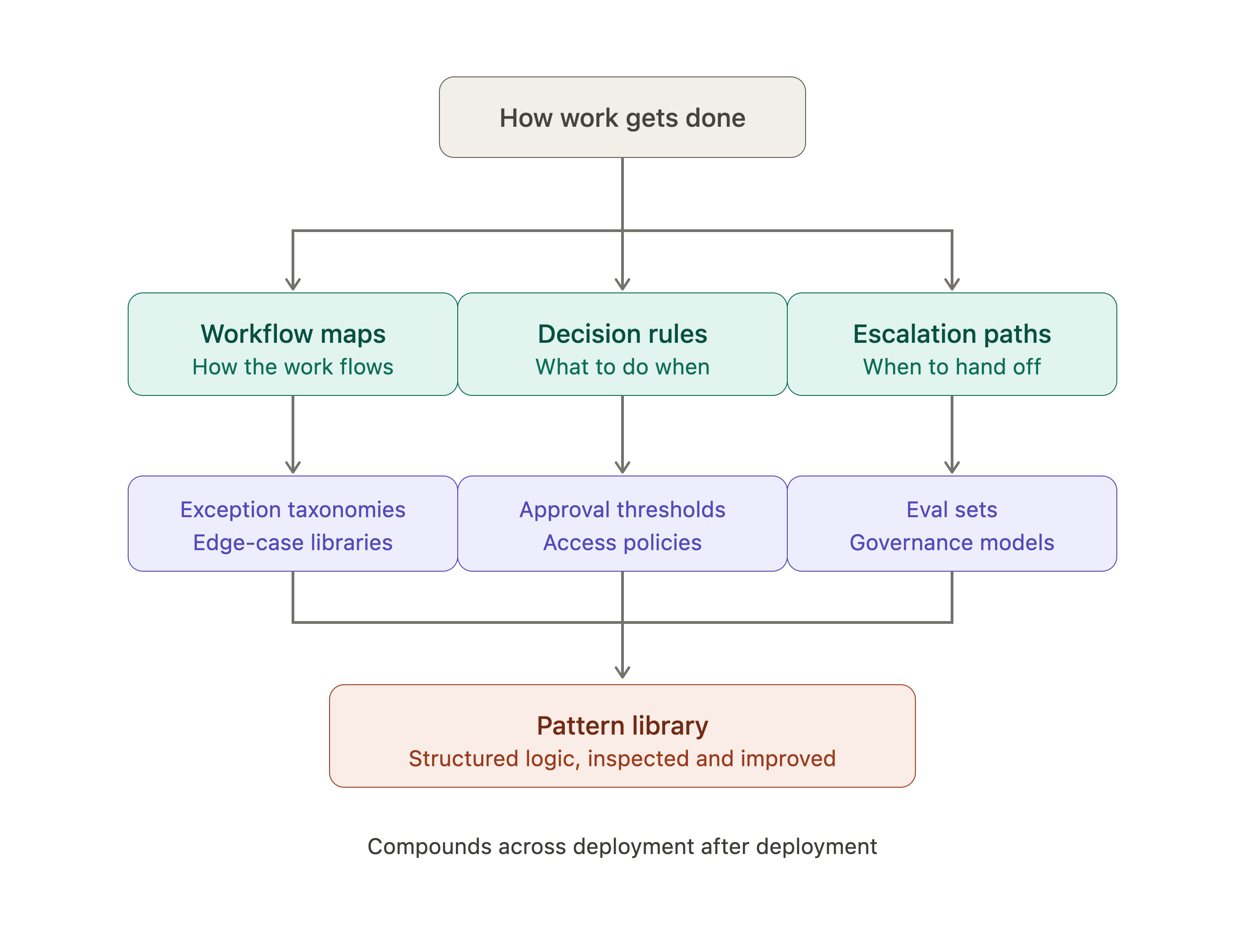
The goal is to create a map of the knowledge tree within a company – things like workflow maps, decision rules, exception taxonomies, escalation paths, eval sets, access policies, approval thresholds, and edge-case libraries. This creates structured logic for an organization that can be inspected and, over time, improved.
Modernization does not mean migration
I’ve argued before that legacy modernization is an important wedge in enterprise AI. This means translating old code into new code and requires a full-system modernization. While this is true, it’s worth noting that sometimes the best first move is to modernize the work around a piece of software rather than the software itself. “We’re not going to force you to migrate off your systems of record, which is the enterprise reality for most companies,” Vas said. “They’re very married to their ERP or their CRM.”
These systems hold years of process and integrations so sometimes it’s easier (and better) to build on top of them. This means connecting them and then extracting the process logic between them. Then give agents the context to execute work across them. “We build on top wherever possible,” Vas said “because there is still so much work to be done that exists on top of these platforms and by interconnecting these systems.”
This approach has limits if the underlying architecture is brittle. This might mean the data isn’t clean, or permissions are broken, and so building on top of these problems means you end up automating around dysfunction instead of fixing it.
The best enterprise AI deployments I’ve seen do some combination. They build on top where possible, then let the agent deployment show what actually needs to be rebuilt. Modernization used to mean making legacy software usable by modern developers. These days, modernization means making legacy operations legible to agents.
The pattern library
Each deployment in services-heavy AI companies looks bespoke. However, there are patterns to be learned in the deployment expertise itself, which makes repeatability across customers easier over time.
For example, after multiple finance department deployments, a company can start to learn patterns around how finance departments run and where they break. Importantly, this compounding doesn’t depend on moving client data around. “We allow our agents to have a higher baseline accuracy,” Vas said, “not because we extract data from our clients, but because we have the methodology and practices best suited for the right-tail edge cases we’ve seen across deployments.” The data from one client does not necessarily need to be copied into another client’s system for the next deployment to improve.
This means you start to learn the workflow archetypes, questions to ask, evaluation harnesses, governance models, etc. Clemens Komorek, CEO of Zalion, which builds AI procurement agents for industrial buyers, sees the value of this at the transaction level. “Every transaction teaches the system something about supplier relationships and negotiation levers,” he told me. “And because supply chains keep shifting, the system has to adapt as outcomes change. This is how localized expertise becomes something repeatable.”
What remains bespoke is the business-specific context. “That part is not repeatable,” Vas said, “because every single business is different. Pretending otherwise is why most AI projects fail.”
The accumulated knowledge is what creates a pattern library and this is the moat. It’s knowing where autonomy belongs and how to turn processes into structured operational logic, built up across deployment after deployment.
Why neither the labs nor the incumbents own this
It is tempting to assume the labs will eventually own enterprise AI deployments because if the models keep getting better, why not just build the agents? And yes, the labs will own a lot of the horizontal intelligence infrastructure, but there’s a difference between selling intelligence versus selling operational transformation.
The labs are optimized for scalable intelligence whereas enterprise transformation is not cleanly scalable. Plus, no enterprise wants its entire company dependent on just one or two model providers because it would make them highly vulnerable.
So there’s still a need for a layer that decides which model belongs where, how to route work, how to control cost, and how to ensure the workflow continues even when the model layer shifts underneath. This is something I wrote about last year – the shift from models to systems.
Consulting firms and legacy systems integrators are the other candidates to own enterprise transformation. They’ve shepherded companies through past technology shifts, and they know how to navigate large organizations. The question is whether they can build and continuously upgrade production AI systems fast enough.
AI moves quickly. Best practices from six months ago are practically obsolete now. “The inertia required to move a large behemoth organization like a McKinsey to become AI-native themselves,” Vas argues, “is insurmountable.” A firm with tens of thousands of employees and decades of internal process inertia may struggle to become AI-native quickly enough to deliver the kind of systems customers actually need.
This is not to say the incumbents will not participate. They will. They already are. But there is an opening for a new category of company that combines consulting-grade process understanding with software-grade deployment velocity. These can be horizontal companies or vertical-specific solutions.
The agent is the mechanism
A company transforms when the relationship across its people, its processes and its outputs change. “Rebuilding a company around AI,” Vas said towards the end of our conversation, “means starting to understand where the processes themselves break down. It’s not about slapping AI on top of operations that aren’t yet designed for it.”
In many cases, this means rebuilding the operating model from the ground up. And in that new model, plenty of work still belongs to humans or to deterministic automation – not to agents. Where an agent actually belongs is something you discover through the deployment process itself. And that’s what compounds – the accumulated knowledge of where autonomy works and how to deploy it.
After all, enterprises aren’t looking to buy an agent. They’re looking to enable their business to be better than it is today, either with more efficiency or with greater outcomes than they could reach before. The agent is just one mechanism.
Author’s note: An LLM was used for light copy editing only (spelling, grammar, and clarity). Content, meaning, tone, and structure remain unchanged.
On point post about enterprise AI. It’s the honest truth where it fits and doesn’t fit. You might hit on data in a future post. You can’t have deterministic agents without AI-ready data.