
The Compounding Advantage: Lessons from Neptune Insurance
Building defensible vertical AI with data loops, write-time guardrails, and tight integration

Neptune Insurance filed its S-1 earlier this month, and it doesn’t read like a typical insurance filing. Neptune is a Managing General Agent (MGA) that uses AI and proprietary data platforms to underwrite and distribute flood insurance. The company is small and tech-heavy: roughly 60 people, about 42% of whom are on the technology team. By contrast, at least a couple well-known, VC-backed “insurtechs” run with single-digit percentages of software developers.
Flood has long been an oddball in U.S. property insurance: huge economic impact, low penetration, and a government-run incumbent (NFIP) that sets the benchmark for pricing and product. For decades that mix, plus regulation and scarce performance data, constrained private innovation. Carriers struggled to price accurately, manage concentration risk, and still deliver a modern experience.
Neptune shows that it’s possible to build a compounding AI advantage in a regulated industry. Below are the lessons that vertical AI companies can learn from its S-1.
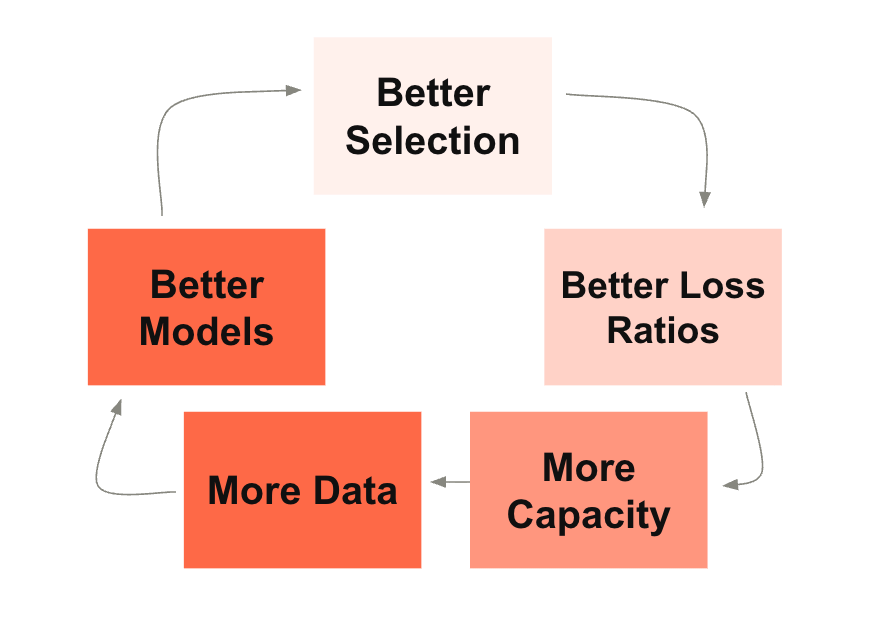
Lesson 1: A Labeled Data Engine
Neptune built Triton (underwriting) and Poseidon (policy) in-house to learn from operations. The system handles 20,000+ quotes a day and has logged ~29.7M quotes, underwritten 11.9M properties, and bound 1.1M policies since launch, which they say is the largest private flood dataset outside the NFIP. Triton makes end-to-end calls (selection, pricing, aggregation control, carrier assignment) in under two seconds, which keeps the flywheel spinning.
Because flood outcomes are observable at the individual-property level, the feedback is clean. That clarity and volume paired with geospatial and other real-time signals enable the models to learn quickly and generalize better.
The foundation of any vertical AI moat is proprietary data that is both plentiful and tied directly to the decisions you’re making. The strongest domains generate a steady stream of labeled events: each decision produces an input, an output, and a ground-truth outcome. In flood insurance, that means millions of quotes and clear loss data at the property level. Every quote request and bound policy becomes fuel for model training, and instant underwriting accelerates the rate of feedback. And while catastrophic losses are lumpy at a single address, across a national book, learning signals are continuous. Such learning signals include:
Risk proxies between events: rainfall totals, river-stage alerts, flood warnings, remote-sensing water presence, parcel elevation/soil/slope, nearby historical claims. These are abundant “weak labels” that help calibrate hazard and vulnerability.
Non-cat losses: nuisance/pluvial events and localized flooding generate many small but informative claims each year.
Cross-sectional diversity: writing across many geographies turns “rare per address” into “frequent in aggregate.” Each season yields numerous labeled episodes somewhere.
This means models improve between storms and take step-changes after each event.
For other regulated industries, the equivalent could be claims data in healthcare, transaction records in finance, or sensor events in energy. What matters is the tight coupling between decision and outcome.
Lesson 2: Guardrails for Model Resilience
Great underwriting models can still break if the portfolio becomes over-concentrated. Neptune solves this with “disaggregation,” which manages maximum loss at the individual property level. Each time a new policy is bound, the system uses radial circles to check concentration in real time and ensure the risk fits within capacity appetites. If a ring is near its limit, the system reprices, routes to a different program, or rejects. Because the limits are encoded as rules with audit logs and what-if sims, the book stays balanced. In addition, decisions are easily explainable and capacity providers can see why a risk was accepted. These guardrails ensure resilience as the models scale.
A high-accuracy model isn’t enough if the system around it can’t enforce safety, compliance, and balance. In regulated markets, infrastructure can ensure each prediction satisfies these macro requirements. Neptune’s “disaggregation” does exactly that. By putting the controls in the transaction flow (instead of reviewing them later), the book stays balanced and the reasoning auditable. For any vertical AI company, it’s critical to have infrastructure that encodes the rules of the domain into the decision loop so the system can scale without breaking.
Lesson 3: Tight Integration
Neptune’s policies are sold through an Agent Portal and instantaneous APIs that plug directly into agents’ quoting flows. This ensures the user experience is seamless and agents don’t need to change their workflows. Agents get bindable quotes in seconds, often generated automatically alongside a standard homeowners or commercial property quote. Crucially, this further fuels the company’s data engine. Every interaction (quotes won and lost, coverage tweaks, endorsements, manual overrides, declinations) flows back as labeled signals. That gives both positive and negative examples, plus reason codes, to train acceptance, pricing, and renewal models without extra ops burden.
Vertical AI companies will win by living where the work happens. This means embedding models and guardrails directly in the workflow and wiring them to the systems of record (AMS, EHR, TMS, WMS, ERP, etc) so outputs write back to the source of truth, trigger the next step, and leave an audit trail. Tight in-flow integration improves data quality and leads to reliable, system-level outcomes.
The Compounding Advantage
Performance attracts capacity; capacity fuels data; data improves performance. Neptune underwrites with no human underwriters and reports consistent overperformance vs the NFIP through 21 landfall hurricanes, including four of the ten largest flood events. For example, in Hurricane Helene (2024), Neptune’s written loss ratio was ~18% vs NFIP’s reported ~163-188%. This track record strengthened Neptune’s relationships across 33 capacity providers, which in turn increased available capacity and commission rates, further accelerating the flywheel.
Flood is particularly well suited to this kind of compounding system: outcomes are observable, decision points are frequent, and each interaction is captured. But the pattern generalizes. In many industries, you can design products that generate labeled data as a byproduct of use and, paired with the right guardrails and integrations, build loops that make the underlying systems smarter and more defensible over time.